
图床还能这么玩?——基于CloudFlare的多存储策略支持的无服务器图床
开端
一直以来,博客的文件和图片成为很多博主的头疼问题,而今天,这个问题将被完美解决。
建议直接跳转到文件床部分。
项目介绍
CloudFlare ImgBed 是一个基于 Cloudflare Pages 的开源文件托管解决方案,为用户提供免费、稳定、高效的文件存储服务。项目支持多种存储渠道,支持无服务器和有服务器部署方式,满足不同用户的需求。
存储渠道
| 渠道类型 | 文件大小限制 | 费用 | 特点 |
|---|---|---|---|
| Telegram Bot | 单文件 20M | 免费 | 稳定可靠,支持压缩 |
| Cloudflare R2 | 无限制 | 10GB用量内免费 | 高性能,企业级 |
| S3 API | 根据服务商 | 根据服务商 | 兼容性强,选择多样 |
| Discord | 单文件 10MB(Nitro 25MB) | 免费 | 简单易用 |
| HuggingFace | 无限制 | 免费 | 支持大文件直传 |
文件管理
- 目录功能:支持创建目录,文件分类管理
- 批量操作:批量删除、移动、加入黑白名单
- 文件搜索:快速查找指定文件
- 详细信息:查看文件大小、上传时间、来源 IP 等
多样化复制
- 原始链接:直接的文件访问链接
- Markdown:
格式 - HTML:
<img src="图片链接">格式 - BBCode:
[img]图片链接[/img]格式
智能功能
- 设置记忆:自动保存用户的上传偏好
- 一键复制:点击链接自动复制到剪贴板
- 错误重试:失败文件支持重新上传
Cloudflare部署
官方部署指南:Cloudflare 部署
Cloudflare Pages 是推荐的部署方式,提供免费托管、全球 CDN 加速和无需服务器维护的优势。
📂 第一步:Fork 项目
- 访问 CloudFlare ImgBed 项目
- 点击右上角的 “Fork” 按钮
- 选择您的 GitHub 账户
- 确认 Fork 完成
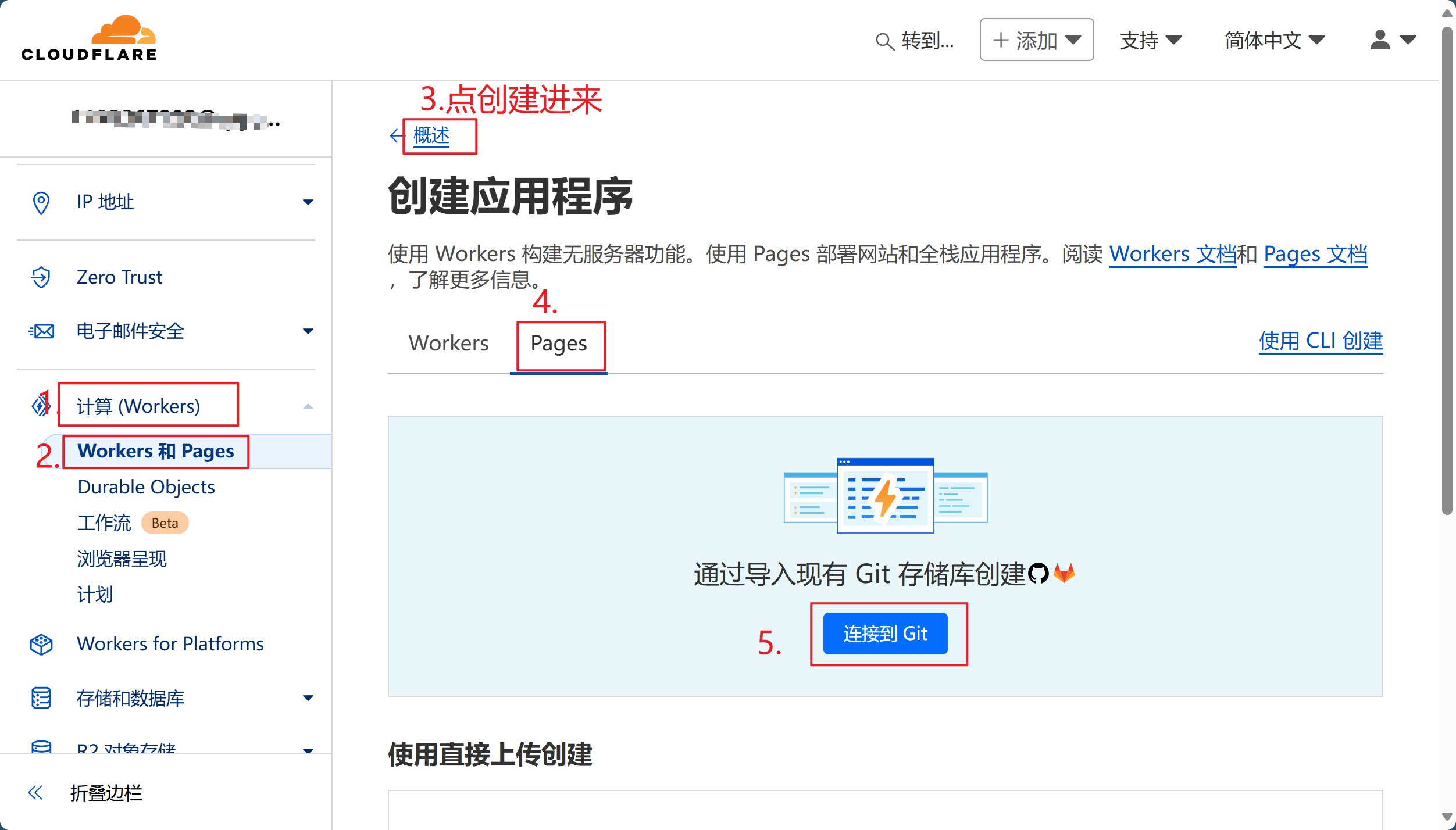
🏗️ 第二步:创建 Pages 项目
2.1 访问 Cloudflare Dashboard
- 登录 Cloudflare Dashboard
- 选择左侧菜单的 “计算和AI” -> “Workers & Pages”
- 点击 “创建应用程序”
- 在最下方
Looking to deploy Pages?<span> </span>选择 “Get started” - 在 “导入现有 Git 存储库” 处点击 “开始使用”
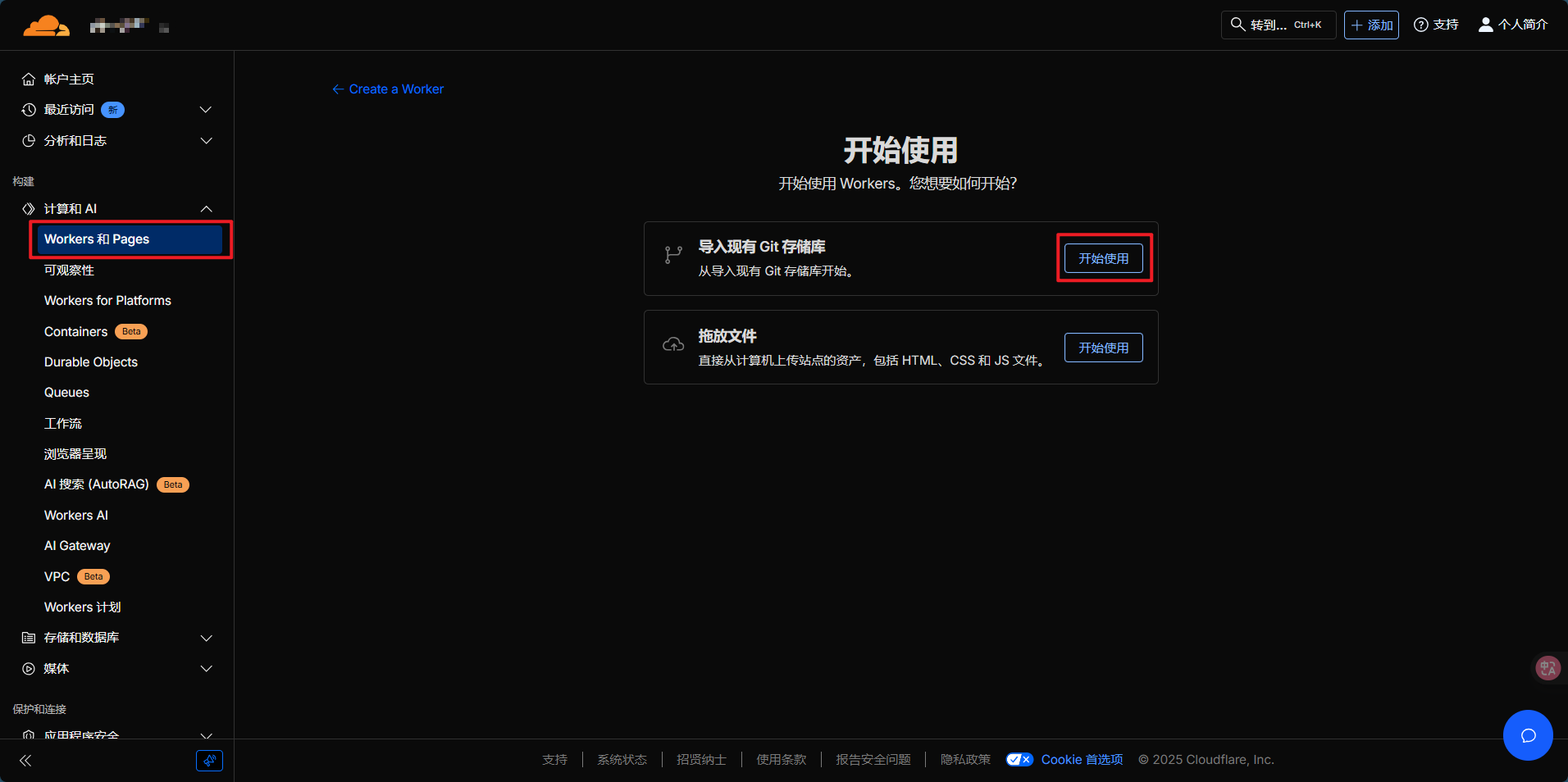
2.2 连接 GitHub 仓库
- 如果首次使用,需要授权 Cloudflare 访问 GitHub
- 选择您 Fork 的
CloudFlare-ImgBed仓库 - 点击 “开始设置”
2.3 配置项目设置
| 配置项 | 值 | 说明 |
|---|---|---|
| 项目名称 | cloudflare-imgbed(或自定义) |
项目标识符 |
| 生产分支 | main |
生产环境分支 |
| 构建命令 | npm install |
重要:v2.0 新构建命令 |
| 构建输出目录 | / |
保持默认 |
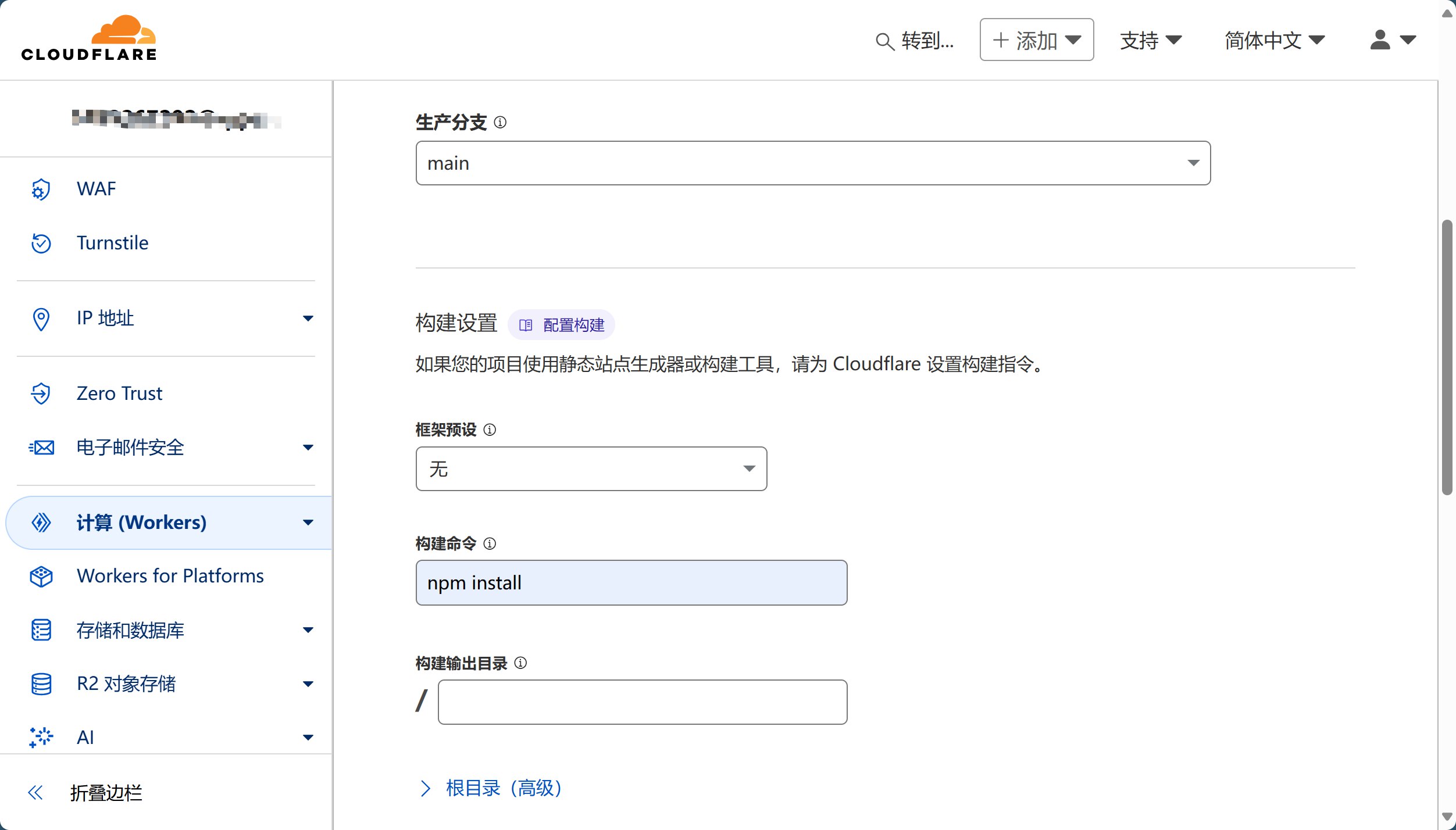
重要提醒:v2.0 版本的构建命令已变更为 npm install,请确保使用正确的构建命令。
2.4 部署项目
- 点击 “保存并部署”
- 等待首次部署完成(约 2-3 分钟)
🗄️ 第三步:配置数据库
数据库用于存储文件元数据,是必需的组件,可选数据库为 KV 数据库和 D1 数据库。两者对比如下表所示,根据自己使用场景从其中选择一种配置即可。
| 特点 | KV 数据库 | D1 数据库 |
|---|---|---|
| 读写性能 | 高 | 较低 |
| 免费额度 | 少 | 多 |
| 大文件上传 | 支持 | 不支持 |
重要提示
KV 数据库和 D1 数据库只需要配置其中一个即可,不需要同时配置两个!建议根据上表选择适合自己的数据库类型。
3.1 KV 数据库配置
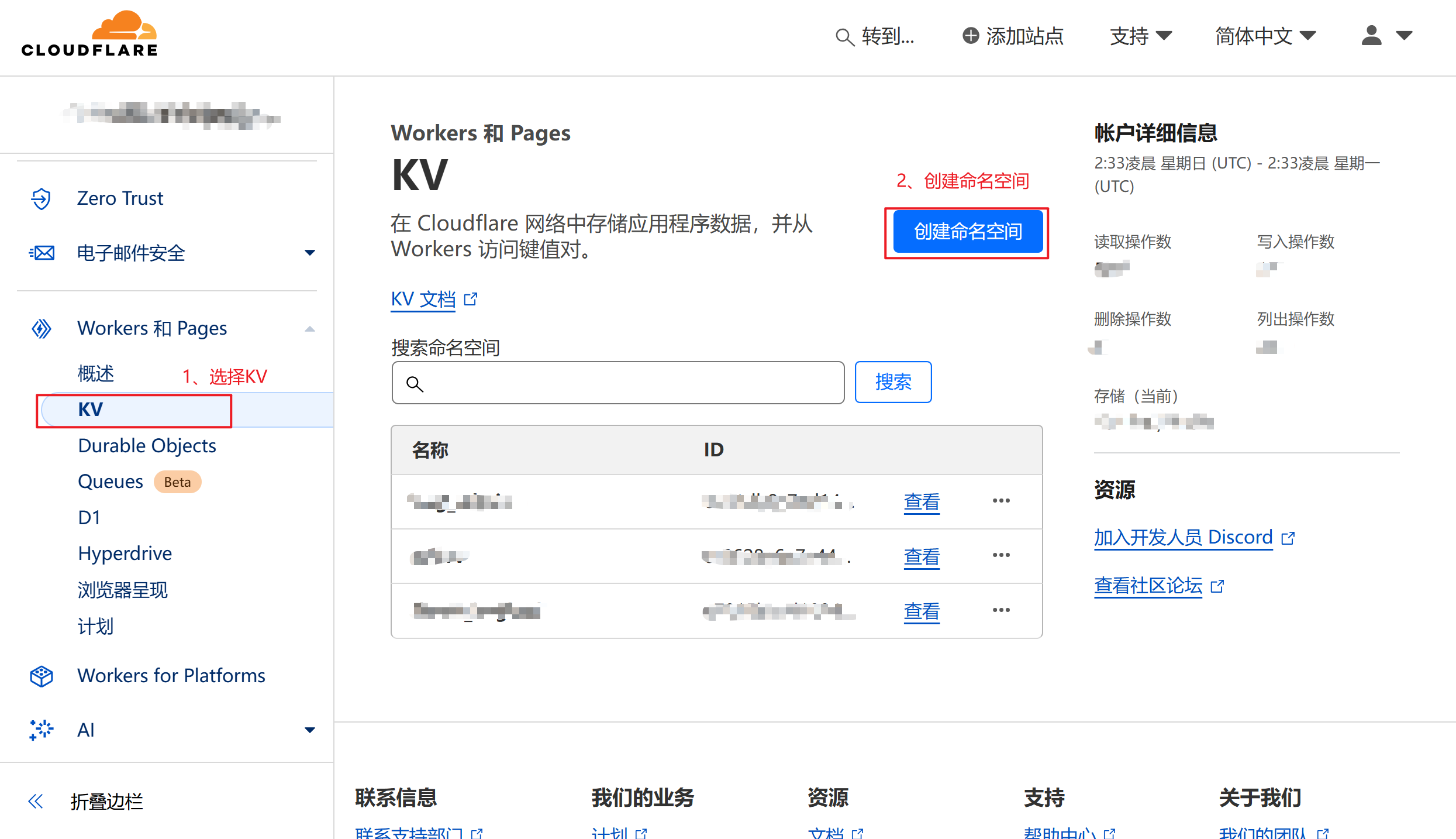
创建 KV 命名空间
- 在 Cloudflare Dashboard 中选择 “存储和数据库”
- 点击 “Workers KV”
- 点击 “创建实例”
- 输入命名空间名称:
img_url(建议使用此名称) - 点击 “创建”
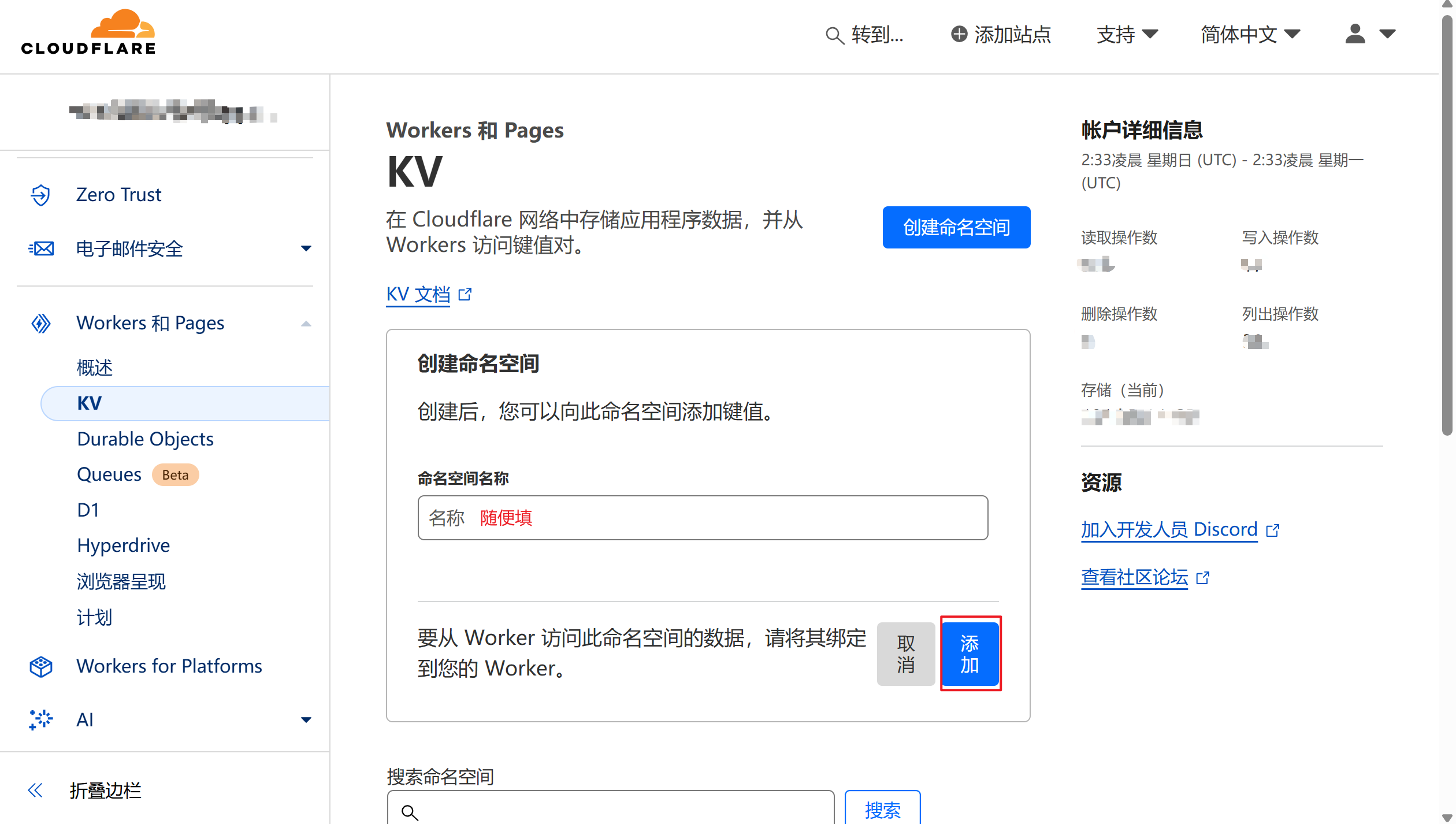
绑定 KV 到项目
- 返回您的 Pages 项目
- 选择 “设置” → “绑定”
- 点击 “添加” → “KV 命名空间”
- 填写绑定信息:
- 变量名称:
img_url(必须是这个名称) - KV 命名空间:选择刚创建的命名空间
- 变量名称:
- 点击 “保存”
注意
绑定 KV 时,变量名称必须为 img_url,这是项目预设的变量名,填错会出现无法进入管理界面等情况。
3.2 D1 数据库配置
创建 D1 数据库
- 在 Cloudflare Dashboard 中选择 “存储和数据库”
- 点击 “D1 SQL 数据库”
- 点击 “创建数据库”
- 输入数据库名称:
img_d1(建议使用此名称) - 点击 “创建”
初始化 D1 数据库
- 创建完成后,点击进入数据库详情页
- 选择 “控制台” 选项卡
- 在 SQL 输入框中粘贴并执行注释区域以下的内容(见项目仓库)
- 点击 “执行”
绑定 D1 到项目
- 返回您的 Pages 项目
- 选择 “设置” → “绑定”
- 点击 “添加” → “D1 数据库”
- 填写绑定信息:
- 变量名称:
img_d1(必须是这个名称) - D1 数据库:选择刚创建的数据库
- 变量名称:
- 点击 “保存”
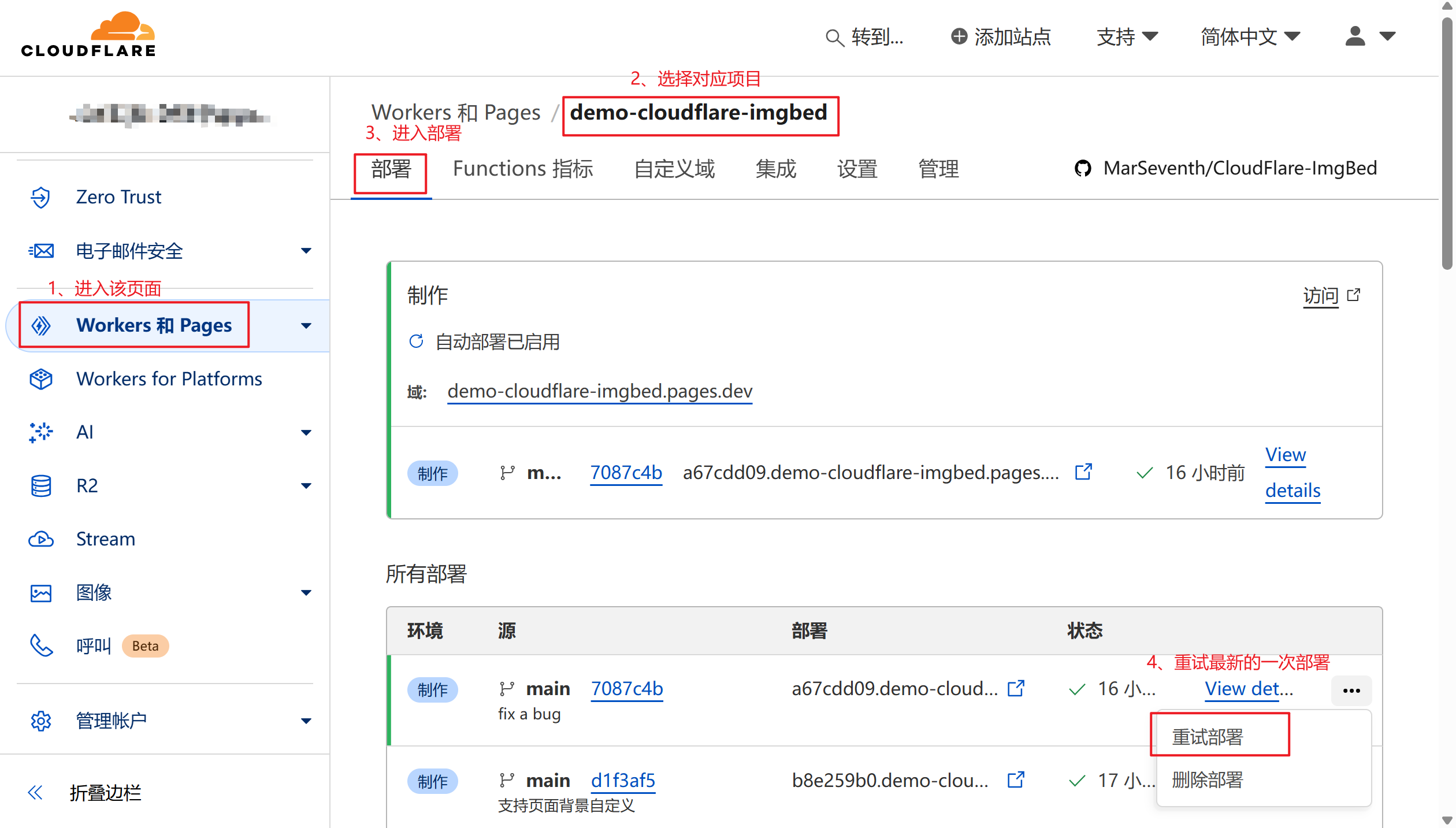
🔄 第四步:重新部署
绑定数据库后需要重新部署以生效:
- 进入项目的 “部署” 页面
- 找到最新的部署记录
- 点击右侧的 “…” 菜单
- 选择 “重试部署”
- 等待部署完成
🚀 下一步
至此已经完成项目在 Cloudflare Pages 的部署,但是尚未添加存储渠道,添加存储渠道和进行其他设置的方式请参考官方配置说明: 配置说明。
总结
0成本,多策略无需服务器的高效图床。
文件床
正片开始。
本文内容的核心不在于图床,因为cloudflare-imgbed这个项目不仅能上传图片,还能上传各种文件。这就给我们
很大的启发。
下面是个人案例分享:
小说床
各位应该都有过创立自己小说站的想法吧,可惜受限于文件存储的影响,决定了服务器存储空间和流量的成本极高,现在你可以用这个项目轻松解决问题。
小说床:基于 Cloudflare 生态的低成本托管方案利用
Cloudflare Workers 的边缘计算能力,将小说章节内容存储在外部廉价/免费空间中,通过 API 或 CDN 节点实时分发,彻底解决服务器带宽和存储瓶颈。策略
策略一:TG-Bot
这种策略利用 Telegram (TG) 对文件上传不限容量的特性,将其作为底层的“冷存储”。实现原理:
后端存储: 通过 Telegram Bot API 将小说文件(TXT、PDF、EPUB)发送至私有频道或对话,获取 file_id。网关映射: 利用 Cloudflare Worker 拦截请求,将小说 ID 转换为 TG 的文件下载链接。
缓存分发: Cloudflare 边缘节点缓存已解析的内容。当读者阅读时,内容从 CF 缓存中吐出,而不直接消耗 TG 的带宽。
策略二:B2/R2存储空间负载均衡
Backblaze B2 拥有极低的价格(约 $6/TB)且与 Cloudflare 签署了“带宽联盟”(Bandwidth Alliance),这意味着 从 B2 到 Cloudflare 的流量费为零。
利用上篇文章提到的批量注册B2账号方案(原理应该同样适用于R2):https://blog.sord.top/posts/b2-multiple-signup.html
在cloudflare-imgbed项目后台开启S3存储负载均衡,并添加大批量免费Bucket的S3 API。
这样,你就实现了小说床的硬核部署。
资源站
策略可复刻小说床中策略2。
还可以通过Hugging Face的公开数据集来完成。
在构建资源站(如软件下载站、视频素材站或大型压缩包托管)时,由于文件体积远大于小说文本,对带宽和存储的稳定性要求更高。除了复刻“B2 + Cloudflare”的方案外,利用 Hugging Face (HF) 作为底层存储是一种极具创新的“降维打击”方案。
以下是针对资源站场景完善后的策略:资源站:大文件高带宽托管方案资源站的核心痛点在于:大文件的存储成本和高频下载产生的流量费。
策略三:Hugging Face 数据集(白嫖大容量高性能存储)
Hugging Face 虽是 AI 平台,但其 Dataset(数据集)功能本质上是一个支持 Git LFS(大文件存储)的无限量对象存储。
实现原理:建立仓库: 在 Hugging Face 创建一个 Public 或 Private 的 Dataset 仓库。文件上传: 利用 Git LFS 或 HF 网页端上传资源(单个文件可达数 GB,总容量几乎无限制)。
直链转换: 通过 Cloudflare-Imgbed项目直接获取直链。
优势:
完全免费: HF 目前不收取存储费和下载流量费。全球加速: HF 背后通常使用高质量 CDN,配合 Cloudflare 缓存后,下载速度极快。
深不可测:HF的公开数据集仓库可供存储量超TB级,想存多少存多少。
更多玩法大家可以自行挖掘,例如TG负载均衡?



